如何用Docker高效部署AI:机器学习模型全流程指南
一、Docker在机器学习场景中的核心价值
在传统机器学习开发中,环境配置是制约项目推进的首要难题。不同开发者的操作系统差异、Python版本冲突、依赖库版本不兼容等问题,常导致”在我机器上能运行”的经典困境。Docker通过容器化技术,将应用及其依赖环境打包为独立镜像,解决了这一核心痛点。
在传统机器学习开发中,环境配置是制约项目推进的首要难题。不同开发者的操作系统差异、Python版本冲突、依赖库版本不兼容等问题,常导致”在我机器上能运行”的经典困境。Docker通过容器化技术,将应用及其依赖环境打包为独立镜像,解决了这一核心痛点。

HunyuanOCR是腾讯混元团队开源的高性能光学字符识别模型,参数量仅10亿。基于混元多模态架构开发,采用端到端设计,能高效处理文字检测、识别及文档解析任务。模型在复杂文档测试中得分94.1分,超越谷歌Gemini3-Pro等主流产品,支持14种小语种翻译。轻量化特性适用于票据识别、视频字幕提取等场景,开源地址为GitHub和Hugging Face平台。
Fara-7B是微软开源发布的70亿参数规模的计算机操作代理(CUA)模型,基于Qwen2.5-VL-7B架构。通过视觉解析网页截图,在屏幕上执行点击、输入等操作,无需依赖额外的可访问性树或多个大模型协作,可直接在Windows 11本地运行,支持NPU加速,实现更低延迟和更好的隐私保护。Fara-7B在WebVoyager、Online-Mind2Web等公开基准测试中表现优异,任务成功率高,部分任务领先同级模型。采用全新的合成数据生成流程进行训练,包含大量任务轨迹和辅助任务数据,以监督微调为主。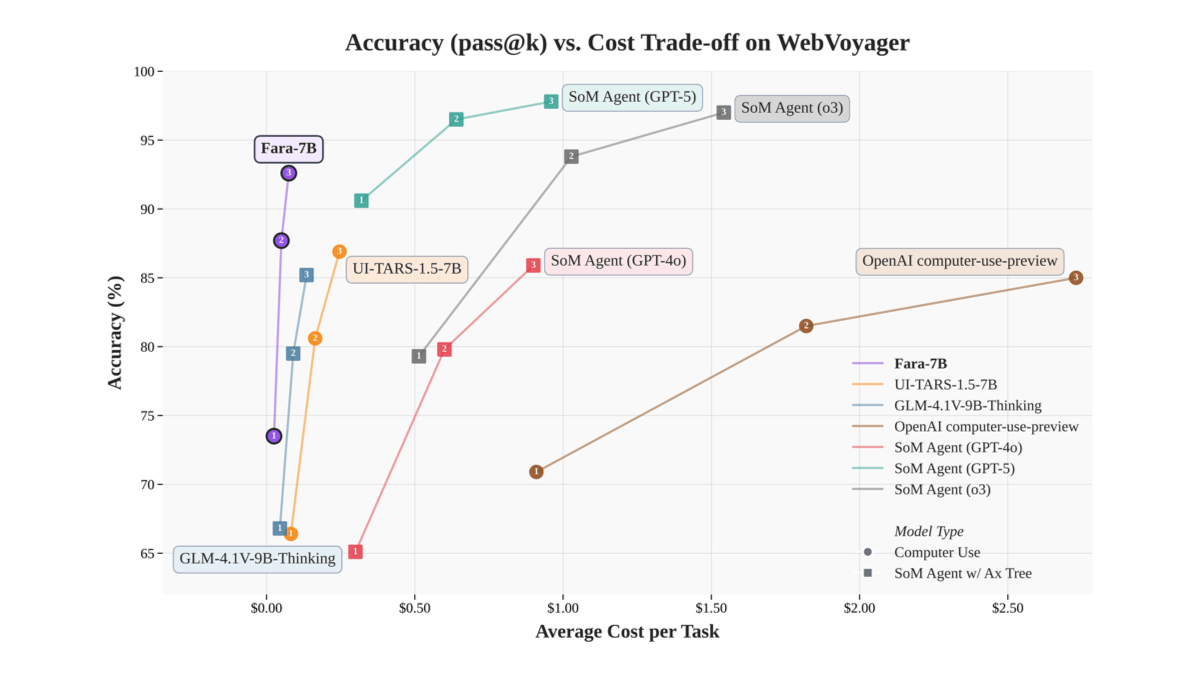
Supertonic是开源的高性能的文本转语音(TTS)系统,专注于在本地设备上快速生成语音。采用ONNX Runtime技术,可在手机、电脑甚至树莓派等设备上运行,支持23种语言和语音克隆,无需网络连接即可实现毫秒级响应。特色在于处理复杂文本的能力,能自然朗读包含数字、符号的非标准文本,适合开发实时语音应用。用户可通过GitHub获取开源代码和模型,支持Python、Node.js等多种编程环境。
MiMo-Embodied是小米集团开源的全球首个成功融合具身智能(Embodied AI)与自动驾驶的跨具身基础模型。解决具身智能与自动驾驶之间的知识迁移难题,实现两大领域的任务统一建模。同步支持具身智能的三大核心任务(可供性推理、任务规划、空间理解)与自动驾驶的三大关键任务(环境感知、状态预测、驾驶规划),形成全场景智能支撑。通过统一架构整合室内操作(如机器人导航、物体交互)与户外驾驶(如环境感知、路径规划)任务,打破传统视觉语言模型(VLMs)局限于单一领域的局限。
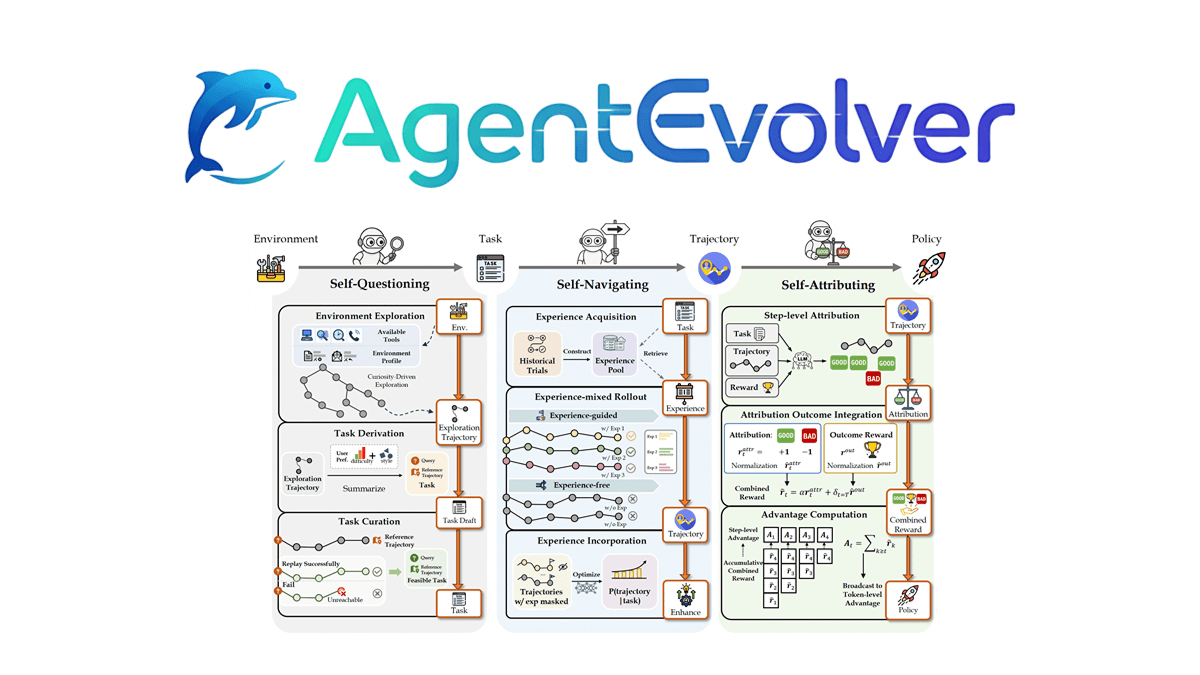
AgentEvolver是阿里巴巴通义实验室开源的智能体进化系统。通过自我提问、自我导航和自我归因三种机制,实现智能体的自主学习与进化。AgentEvolver采用服务导向架构,将环境沙盒、LLM和经验管理模块化,支持多种外部环境和工具API的无缝集成。其优势在于高效学习、成本效益和持续进化能力。与传统强化学习方法相比,AgentEvolver在探索效率、样本利用率和适应速度上表现出色,减少了人工数据集的依赖和随机探索成本。AgentEvolver的框架代码已开源,为开发者提供了灵活的定制和开发空间。