为什么现代 AI 能做成?Hinton 对话 Jeff Dean
2025 年 12 月初,圣地亚哥 NeurIPS 大会。Geoffrey Hinton(神经网络奠基人、2024年诺贝尔物理学奖得主)与Jeff Dean(Google首席科学家、Gemini模型联合负责人、TPU架构师)的炉边对谈,成为这场大会的重要时刻。
2025 年 12 月初,圣地亚哥 NeurIPS 大会。Geoffrey Hinton(神经网络奠基人、2024年诺贝尔物理学奖得主)与Jeff Dean(Google首席科学家、Gemini模型联合负责人、TPU架构师)的炉边对谈,成为这场大会的重要时刻。
一个通过与 AI 结对编程,将想法变为现实的终极工作站
小米正式发布并开源全新 MoE 架构大模型 Xiaomi MiMo-V2-Flash。以 “极致效率” 为核心定位,在参数量、推理速度、任务性能与成本控制上实现多维突破。
混元世界模型1.5(Tencent HY WorldPlay)是腾讯发布的业界首个开源的实时世界模型框架,涵盖数据、训练、流式推理部署等全链路。核心是WorldPlay自回归扩散模型,采用Next-Frames-Prediction任务训练,破解了实时性与几何一致性难题。实时交互生成,通过原创的Context Forcing蒸馏方案和流式推理优化,能以每秒24帧的速度生成720P高清视频;长范围3D一致性,借助重构记忆机制,支持分钟级内容的几何一致性生成;多样化交互体验,适用于不同风格场景及第一、第三人称视角。
SAM Audio是Meta推出的开源多模态音频分割模型,从复杂的音频混合中精准分离出任意目标声音。通过结合文本、视觉和时间维度的提示,实现灵活、高效的音频处理,为音频编辑、去噪、声音提取等任务提供了全新解决方案。用户可以通过简单的文本描述(如“吉他声”)、在视频中点击发声物体,或者标记声音出现的时间范围来使用SAM Audio。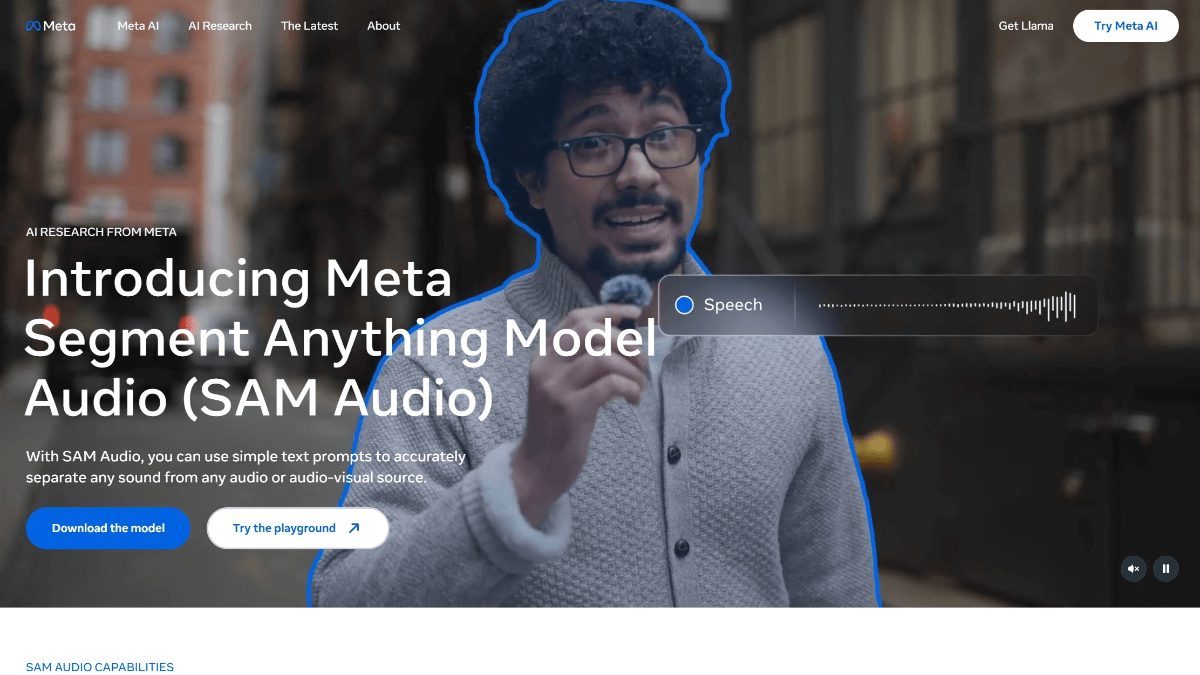
A2UI(Agent-to-User Interface)是谷歌开源的Agent驱动型界面协议,解决AI代理生成复杂交互界面的难题。通过一种声明式JSON格式,让AI代理描述用户界面的结构,客户端应用(如Flutter、Angular等)将这些描述转换为原生组件,实现跨平台兼容与动态更新。A2UI的核心优势在于其非执行代码特性,所有UI描述均为静态数据,不执行代码,从而规避了LLM生成代码的安全风险。支持渐进式渲染,适配对话场景中的实时交互需求,并且框架无关,同一JSON配置可以在不同平台渲染。能根据对话上下文动态生成表单、地图等组件。例如订餐时,AI可直接弹出带日期选择器的界面,避免繁琐问答。项目已集成至Gemini 3模型,可通过GitHub快速体验餐厅预订等Demo案例。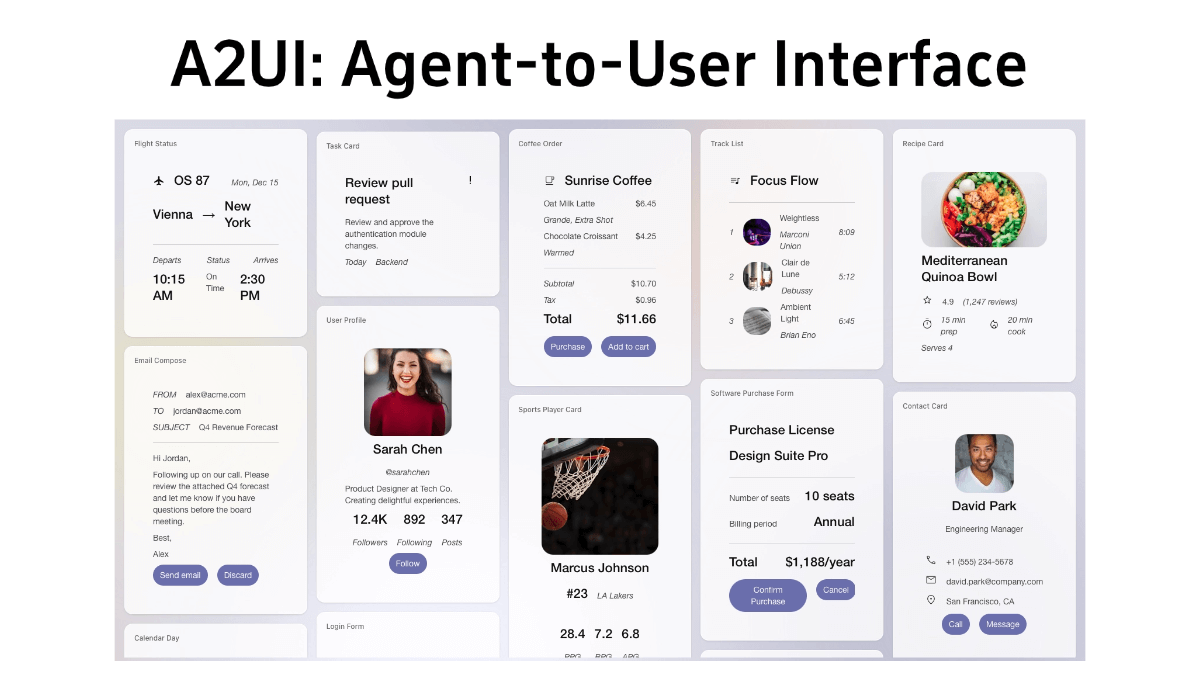
Wan-Move是阿里通义实验室、清华大学等机构联合开发的开源AI视频生成框架,专注于通过精准运动控制技术实现高质量视频合成。核心技术是"潜在轨迹引导",能在现有图像到视频模型基础上无缝添加点级运动控制,支持5秒480P视频生成,运动控制精度超越主流开源方案22.5%。框架无需修改基础模型架构,通过复制第一帧特征到后续帧实现运动注入,适用于单目标、多目标及复杂场景(如多人互动、物体交互),并在MoveBench基准测试中取得FID 12.2、EPE 2.6的顶尖性能。用户可通过ComfyUI插件或云端平台体验,模型已在GitHub开源。
